Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod
Get SIGNAL/NOISE in your inbox daily
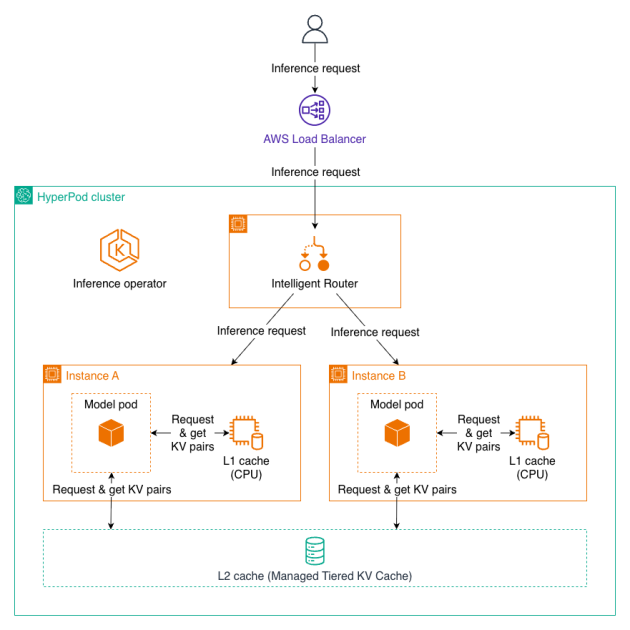
In this post, we introduce Managed Tiered KV Cache and Intelligent Routing for Amazon SageMaker HyperPod, new capabilities that can reduce time to first token by up to 40% and lower compute costs by up to 25% for long context prompts and multi-turn conversations. These features automatically manage distributed KV caching infrastructure and intelligent request routing, making it easier to deploy production-scale LLM inference workloads with enterprise-grade performance while significantly reducing operational overhead.
Recent Stories
Jan 31, 2026
Autonomous cars, drones cheerfully obey prompt injection by road sign
: AI vision systems can be very literal readers
Jan 31, 2026NVIDIA is still planning to make a ‘huge’ investment in OpenAI, CEO says
Bloomberg reports that CEO Jensen Huang said NVIDIA's investment in OpenAI could be the largest the company has ever made.
Jan 31, 2026AI Agent Engineer at CollectWise
About Us CollectWise is a fast growing and well funded Y Combinator-backed startup. We’re using generative AI to automate debt collection, a $35B market in the US alone. Our AI agents are already outperforming human collectors by 2X, and we’re doing so at a fraction of the cost. With a team of three, we scaled to a $1 million annualized run rate in just a few months, and we are now hiring an AI Agent Engineer to help us reach $10 million within the next year. Role We are hiring an AI Agent Engineer to design, optimize, and productionize the...